Tiffany Chen
Marketing
Share this article
Tiffany Chen
Marketing
Share this article
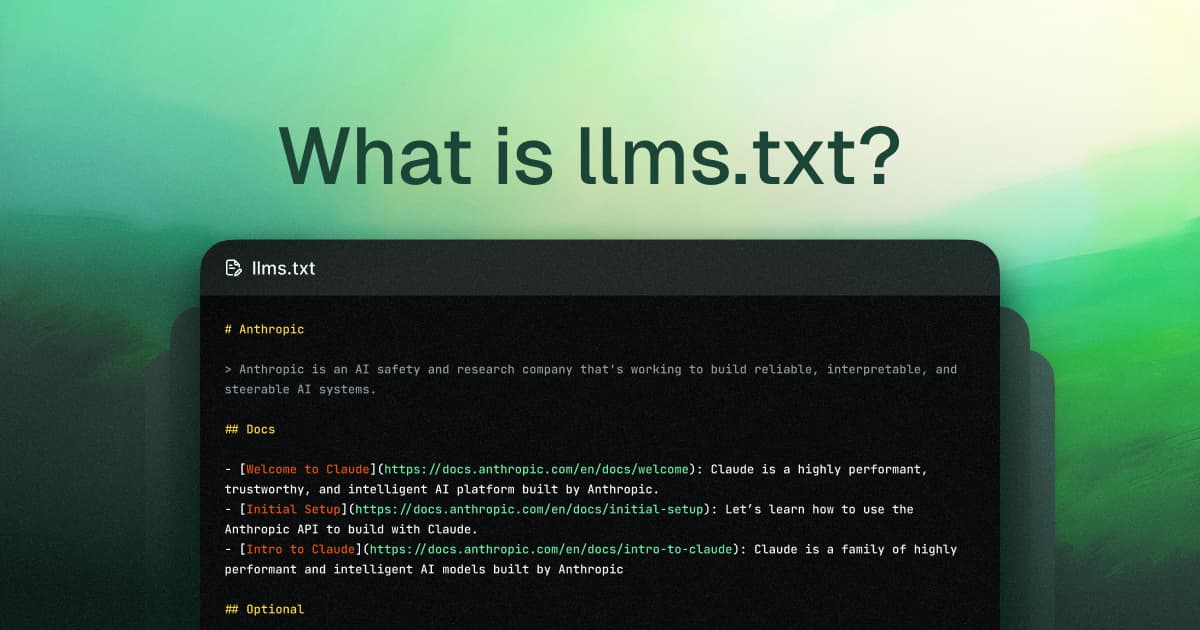
llms.txt is a new standard that structures web content in plain Markdown to help large language models understand and index documentation more effectively. This simple file, served at /llms.txt, provides AI crawlers with a clear outline of your most important content, improving how your documentation appears in AI-generated answers and search results.
This post was updated on March 14, 2026 to reflect the latest developments in llms.txt.
llms.txt is a plain Markdown file hosted at /llms.txt on your website that provides a structured summary of your most important content for large language models. Think of it as a recommended reading list for AI: it tells LLMs what your site is about, what content matters most, and where to find it, without the noise of HTML, JavaScript, or ads.
Since Jeremy Howard, co-founder of Answer.AI, first proposed /llms.txt in September 2024, the currents of the conversation around this standard have changed. Adoption remained niche until November, when Mintlify rolled out for /llms.txt across all docs sites it hosts. Practically overnight, thousands of docs sites—including Anthropic and Cursor—began supporting llms.txt.
But while the most popular developer companies like Cloudfare, Vercel, Anthropic, and Astro stand behind it, some big names in the world of SEO have refuted it.
Here’s what we know for sure: Optimizing for AI has different goals than optimizing for search engines. If you’re using llms.txt to boost traffic and win in search engine results pages (SERPs), then you’re likely not getting ideal results. But if you’re looking to give AI agents better context, faster, then you’re on the right track.
llms.txt adoption is early, but the trajectory is clear. Having structured, agent-readable content is a rehaul you’ll need to take on sooner or later.
What is llms.txt?
llms.txt is a plain Markdown file served at /llms.txt on your website. It provides a lightweight summary of your most important content, structured in a way that's easy for LLMs to read—without the clutter of HTML, Javascript, or advertisements.
Here's what an llms.txt file can include:
- An H1 title (this is the only required section for the file)
- A short summary of the site, usually in a blockquote
- Details about how the site is structured or how to interpret provided files
- H2 sections, each with Markdown-formatted lists of important links
- An“Optional” section to flag lower-priority resources that can be skipped if needed
An example llms.txt file:
# Example Product Docs
> Learn how to get started, use the API, and explore tutorials.
## Guides
- [Getting Started](<https://example.com/docs/start>): Intro guide
- [Install](<https://example.com/docs/install>): Setup steps
## Reference
- [API](<https://example.com/docs/api>): Endpoint list and usage
Aside from /llms.txt serving as the outline of your site, the standard also proposes providing more web content in markdown in general.
- llms-full.txt: Compile all of your site's text into a single markdown file, to make it easier to paste a single URL to load context into an AI tool. This file structure was developed by Mintlify in collaboration with customer Anthropic, and subsequently included as part of the official llms.txt proposal.
- .md: Provide a markdown version of a page by appending .md to the original URL.
How is llms.txt different from robots.txt?
While both files live at your domain root and provide instructions about your site's content, llms.txt serves a fundamentally different purpose than traditional crawler standards:
| robots.txt | llms.txt |
|---|---|
| Controls crawler access | Provides structured content |
| Binary permission system (allow/disallow) | Curated links with descriptions and priority signals |
| Static rules for all crawlers | Curated guidance for specific content |
| Built to prevent unwanted crawling by search bots | Built to improve LLM and AI agent understanding |
llms.txt vs robots.txt vs sitemap.xml
| robots.txt | sitemap.xml | llms.txt | |
|---|---|---|---|
| Purpose | Control crawler access | List all URLs for indexing | Curate key content for LLMs |
| Format | Custom syntax | XML | Markdown |
| Audience | Search engine bots | Search engine bots | LLMs and AI agents |
| Content | Allow/disallow rules | URL list with metadata | Structured links with descriptions |
| Scope | What not to crawl | Everything to index | Curated subset of key content |
The simplest analogy: if your site were a physical library, sitemap.xml is the complete catalogue, robots.txt marks the restricted shelves, and llms.txt is the librarian’s recommended reading list.
For developer tools, this difference matters. Marketing teams might use robots.txt to control SEO crawling, but developers building with and for agents need the content architecture that llms.txt provides.
Why should you use llms.txt?
LLM traffic is still early, but it's projected to jump from 0.25% of search in 2024 to 10% by the end of 2025.Adding llms.txt now ensures you're in control of how your content shows up as AI continues to reshape how people explore the web.
llms.txt helps:
- Surface key content quickly: Guides, references, tutorials—whatever matters most.
- Reduce model error: Structured links are easier to parse and reason about.
- Improve user experience: When someone asks an AI “How do I get started with X?”—you want the answer to come from you.
When Howard proposed the llms.txt standard, his aim was to make it easier for LLMs to parse large volumes of website information from a single location. Parsing unstructured HTML is slow and error-prone for models. Plain Markdown files served as the perfect bridge between human-readable documentation and structured data for AI systems. This means:
Faster content parsing with fewer errors
llms.txt helps a ChatGPT or Claude immediately understand your documentation structure, for instance, without crawling multiple pages or parsing complex navigation elements. It also filters out ads, HTML markup, or JavaScript-rendered elements to optimize token usage.
For developers using AI coding assistants or building agents, this translates to more accurate, context-aware suggestions that align with actual guidance from tools themselves.
Take Vercel as an example: The llms.txt file for their API docs includes contextual descriptions for agents to make better decisions on what API endpoints to fetch.

Efficient token usage
As one developer noted, an agent fetches a lot of “noise” from an HTML page that wastes context windows and burns through tokens.
When done right, we've seen companies report up to 10x token reductions when serving Markdown instead of HTML. But how you generate your llms.txt matters; take Turborepo's llms.txt using up 116,000 tokens as a cautionary tale.
Windsurf, for example, uses Mintlify to host all their docs with /llms.txt to reduce token usage and save agents time.

“Is llms.txt really a thing?”
That’s an actual user prompt we found in Profound, by the way. But generally, the big debate about llms.txt has been if it’s really a standard worth optimizing for.
Not everyone is convinced llms.txt is worth the effort. The most notable criticism is that no major AI company officially supports the format; though Anthropic did partner with Mintlify to generate an llms.txt file for their documentation.
The loudest critics of llms.txt come from those looking to boost their website’s visibility in SERPs.

But here’s the thing: the strongest use cases for llms.txt aren’t around the broad visibility that traditional SEO is gunning for.
Like the standard’s proposal outlines, the end goal is context awareness. The companies seeing the most success have implemented llms.txt not for discovery, but for usability.
With that being said, developer-focused companies are already seeing value in using llms.txt to help users get the right doc suggestions and API examples from AI coding tools, reduce token usage for RAG pipelines, and signal agents to the right places.
Some data to back it up
We found some interesting data from an experiment highlighted in Context Engineering for Agents by Latent Space. In the podcast, LangChain talks about how they ran internal benchmarks testing four different approaches for giving coding agents access to documentation: stuffing all docs into context, vector search with retrieval, basic llms.txt with URL loading, and optimized llms.txt.
Here’s what they found.

As you can see, it was not a close race. Agents using llms.txt can reason about which documentation to fetch based on descriptive context, rather than relying on semantic similarity matching that often misses the mark. We also have more interesting data we found with our friends at Profound, an answer engine optimization platform. We learned that not only are AI agents actively visiting a site’s llms.txt file, they’re actually visiting a site’s llms-full.txt over twice as much.
llms.txt example use cases
Teams are already putting llms.txt into practice to make their content easier for AI tools to understand and use.
You can browse hundreds of live examples at llmstxt.site and directory.llmstxt.cloud.

Here are top examples for llms.txt:
- Documentation: Companies like Pinecone and Windsurf use
llms.txt(via Mintlify) for their developer documentation, making their API references, SDKs, and tutorials discoverable and ingestible by AI. This helps AI applications generate more accurate, contextual answers about how to use your product, grounded in your up-to-date documentation. - Website structure: Companies like Svelte.dev or Rainbowkit use llms.txt as a file structure for important links in their site.
- Website messaging: Companies like Wordlift or Tiptap add llms.txt to their marketing site with both link structure and additional context about their messaging, to guide AI applications in how to interpret and position their product.
How to get started
If you're using a documentation platform like Mintlify, /llms.txt, /llms-full.txt, and .md versions of your docs are generated automatically.
If you're setting it up manually:
-
Create the file in Markdown
- Start with a # heading (site title)
- Add a short blockquote with a summary
- Include sections (##) for key content areas
- Under each, list important links using standard Markdown bullets and links
- Optionally include an “Optional” section for lower-priority pages
-
Host it at /llms.txt
- Place it in the root directory of your site, just like robots.txt (or in a relevant subpath like /docs/llms.txt if needed)
- Make sure the raw text is accessible at that URL
You also don't need to start from scratch. Tools like llmstxt.new let you generate a draft just by prepending a URL.
For more details or to follow updates to the spec, visit llmstxt.org.
llms.txt helps you create AI-native documentation
While we can't yet track whether this improves rankings in AI search results, we’re clearly seeing more practical success: developers reporting that AI tools provide more accurate suggestions when working with codebases that reference well-structured llms.txt documentation. For many companies, llms.txt is part of a broader strategy for AI-friendly documentation that includes:
- Structured markdown to paste directly into ChatGPT, Claude, or Cursor without reformatting
- MCP servers for coding assistants can query your entire docs site in real-time
- AI assistants embedded directly in documentation for instant troubleshooting
That’s what Coinbase did to their documentation experience. Coinbase introduced its AI-native documentation improvements so developers of all skill levels could interact with docs in their favorite AI tools. “AI-native docs aren’t just helpful. They’re now essential when you’re building with tools like MCP and x402,” Coinbase’s Kevin Leffew tells Mintlify.
You get to decide what’s next for llms.txt
AI-focused companies are already moving forward with interesting product implementations based on llms.txt. Vercel embedded llms.txt-style instructions directly in HTML responses, so agents hitting protected pages get authentication steps directly in the 401 error. LangChain built mcpdoc, an MCP server that exposes llms.txt to IDEs like Cursor and Claude Code so developers get full control over how agents fetch and audit documentation context.
We argue that waiting for llms.txt to become a universal standard isn’t the point. If you want to give developers and users more free reign to interact with your content as an AI context layer, then llms.txt is a simple step forward. Platforms like Mintlify now generate both llms.txt and MCP servers automatically—turning documentation into an interface layer between your product and AI tools.
If you're interested in learning how to make sure your documentation is as AI-forward as Anthropic, Cursor, and Bolt.new, get in touch.
Frequently asked questions
Is llms.txt an official standard?
Not yet in the way that robots.txt is an RFC. It's a community-driven proposal by Jeremy Howard of Answer.AI. Adoption is growing: thousands of sites now serve /llms.txt, and the format has been adopted by companies like Anthropic, Cloudflare, and Vercel. The IETF has launched an "AI Preferences Working Group" for related standards, but llms.txt itself is not part of that effort yet.
Where should llms.txt live on my site?
At the root of your domain: example.com/llms.txt. If your docs live on a subpath, you can also serve it at /docs/llms.txt. The key is that it's accessible via a direct URL as raw Markdown.
What is llms-full.txt?
llms-full.txt compiles all of your site's text into a single Markdown file. It lets developers paste a single URL to load full context into AI tools like ChatGPT or Claude. This format was developed by Mintlify in collaboration with Anthropic and is now part of the official llms.txt proposal.
Do AI crawlers actually use llms.txt?
Yes. Data from Profound shows AI agents actively visit /llms.txt files, and visit /llms-full.txt at over twice the rate. LangChain's internal benchmarks also showed that agents using llms.txt significantly outperformed vector search and context stuffing approaches.
Who should create an llms.txt file?
Teams with structured technical content that developers are already feeding into AI tools: API references, SDK docs, integration guides. If your docs are fewer than 10 pages or you don't have API references, the ROI is low. Focus on llms.txt when you have meaningful technical content that AI coding assistants and answer engines should be able to surface accurately.
Does llms.txt affect SEO rankings?
No direct evidence that llms.txt influences traditional search rankings. Its value is in AI search: helping LLMs cite your content accurately in AI-generated answers. If you're optimizing purely for Google SERPs, llms.txt won't move the needle. If you care about how your product shows up in ChatGPT, Perplexity, or Gemini responses, it matters.
How often should I update llms.txt?
Every time you ship significant documentation changes: new API versions, new product features, restructured content. If you're on Mintlify, this happens automatically on every deploy. If you maintain it manually, tie updates to your docs release process.
More blog posts to read

How Claude Code's documentation team makes feedback actionable with Mintlify
Anthropic's Technical Content Engineer for Claude Code shares how she uses Mintlify and Claude to automate documentation improvements from user feedback.
June 25, 2026Ethan Palm
Technical Writing

Docs as an abstraction layer for coding agents
A large engineering org ran controlled experiments to measure how structured Mintlify docs affect agent performance on massive codebases. The results: 64% more precise, 39% more discoverable, half the tokens, 1.5x faster.
June 8, 2026Han Wang
Co-Founder